1. Introduction
For roughly two and a half decades, the brand-discovery infrastructure of the public web operated under a stable model. Users posed queries to search engines. Search engines returned ranked lists of links. Users selected from the lists. Brands competed for position in those lists, and the work of being findable — establishing presence on the public web, structuring content for algorithmic ranking, earning authoritative inbound links — was the province of the discipline known as search engine optimization. The work was understood. The success criteria were measurable. The competitive field was legible.
The model held because the discovery surface was structurally consistent. A brand’s job was to occupy useful positions in a list of links and to convert clicks from those positions into customers. Everything else — credibility, recognition, recommendation — was understood to be the cumulative byproduct of doing those two things well over time, captured indirectly through brand awareness measurement and other proxy instruments.
The model breaks when the discovery surface is no longer a list. When a user asks an AI assistant what is the best CRM for a hospitality startup, the assistant does not return a list of links to be evaluated. It returns a recommendation. The brand’s job is no longer to occupy a position in a list — there is no list. The brand’s job is to be the recommendation.
Being the recommendation requires conditions that the existing measurements of brand authority — PageRank for link-graph centrality (Page et al., 1998), Domain Authority for backlink-graph reputation (Moz, industry-standard), the E-E-A-T framework for human-rater evaluation of expertise, experience, authoritativeness, and trustworthiness (Google, 2022), and brand authority in the strategic marketing tradition (Aaker, 1996) — were not designed to measure. The conditions are:
- Machine-recognizable — the brand has entity-level structured data, clear identity signals, presence in knowledge graphs, and disambiguation from similarly-named entities.
- Machine-credible — the brand’s content carries depth and originality, attribution patterns, claim density, and the signals AI systems use to estimate trustworthiness without a human in the loop.
- Machine-citable — the brand’s content is formatted for chunked retrieval, surfaceable as quotations, structured to be referenced rather than merely browsed.
- Machine-trusted through external validation — the brand has citation patterns from authoritative sources, knowledge graph depth, recognition by third parties, and inclusion in AI training corpora.
Each of these is a stage of work. Each requires its own discipline, its own measurement, its own ownership within an organization. Search engine optimization, calibrated for an earlier discovery surface, does not specify any of them. The emerging tactical disciplines — Generative Engine Optimization, Answer Engine Optimization, AI Optimization — each address one of these tactical surfaces in isolation, without a strategic discipline above them.
This paper introduces Authority and Visibility Optimization (AVO) as the discipline that does specify them. AVO is positioned as the AI-era counterpart to existing authority measurement — building on the established concept rather than replacing it, but calibrated for the discovery surface that synthesized AI answers represent. AVO is organized as three contributions:
- A conceptual framework that defines brand discovery in the AI search era and positions the discipline as the umbrella above the tactical layer.
- The OMG Protocol: a methodology of three pillars and thirty canonical actions specifying the work practitioners perform to engineer authority and visibility.
- A paired measurement model: the Authority Score as predictive measurement of citation readiness, the Visibility Score as empirical measurement of citation outcome, with the two scores forming the diagnostic baseline and outcome verification of an operational practice loop.
The remainder of this paper is structured as follows. Section 2 surveys existing authority measurements and emerging frameworks (GEO, AEO, AIO, AIVO Standard, AAO, AIEO, Architecture of Authority) and identifies the structural gap that AVO addresses. Section 3 introduces the AVO discipline. Section 4 specifies the OMG Protocol. Sections 5 and 6 specify the Authority Score and the Visibility Score respectively. Section 7 describes the AVO practice loop — the closed cycle of AS, OMG, and VS as a coordinated operational pattern. Section 8 specifies the multilingual commitment. Section 9 discloses the empirical implementation context. Section 10 acknowledges limitations and anticipated future work. Section 11 concludes.
2. Background and Related Work
The AI search era has produced a proliferation of new acronyms and emerging frameworks. Each addresses some part of the brand-discovery problem in this era; none addresses it as a coherent discipline that combines a conceptual frame, a methodology, and paired measurement instruments connected by an operational loop. This section surveys the relevant prior work and identifies the structural gap that motivates AVO.
2.1 Authority measurement before the AI search era
Authority is a well-established concept. The information retrieval literature, the search engine optimization industry, and the marketing discipline of brand strategy have each developed measurements of authority across more than two decades.
PageRank (Page, Brin, Motwani, & Winograd, 1998) introduced authority measurement as a graph-centrality computation. A page’s authority was a function of the authorities of the pages that linked to it, computed iteratively across the entire web’s link graph. PageRank framed authority as objectively measurable through the structure of inter-page reference. It became the foundation on which the modern web search infrastructure was built and remains an influential model for graph-based authority measurement in many domains.
Domain Authority (Moz, 2012 onward) extended the link-graph model to whole-domain authority scoring. Domain Authority and the analogous tools from Ahrefs (Domain Rating) and Semrush (Authority Score) became the operational instruments through which the SEO industry measured brand authority for ranking purposes. These tools share PageRank’s structural intuition: authority is what other authoritative sites confer through links and references.
E-E-A-T — Experience, Expertise, Authoritativeness, Trustworthiness — was formalized as an evaluation framework within Google’s Search Quality Rater Guidelines, with Experience added in December 2022 (Google, 2022). E-E-A-T does not directly drive search algorithm ranking; it is the criteria framework used by human raters to evaluate whether search results meet quality expectations. Its publication formalized authority as a multi-dimensional construct combining first-hand experience, domain expertise, organizational authoritativeness, and trustworthiness. E-E-A-T marked a shift from purely structural authority measurement (links) toward measurement that incorporates content-quality signals.
Brand authority in the strategic marketing tradition (Aaker, 1996) is older still. It treats authority as a function of consistent communication of expertise and value to a defined audience over time. Brand authority is measured through brand recognition surveys, share-of-voice analysis, and qualitative reputation assessments rather than through structural web-graph computation.
These four traditions — PageRank, Domain Authority, E-E-A-T, and brand authority — have each contributed to how authority is understood and measured. They were each calibrated for specific discovery surfaces: PageRank and Domain Authority for crawler-based search ranking; E-E-A-T for human evaluation of search quality; brand authority for human-mediated brand recognition.
2.2 The new discovery surface and what it requires
The AI search era introduces a discovery surface unlike any of these. Synthesized AI answers neither rank a list nor reflect human-rater evaluation nor reflect cumulative brand recognition through traditional channels. They reflect what AI systems learned during training and what AI systems retrieve at inference time. The conditions that determine whether a brand is treated as authoritative for AI-mediated answers are different from the conditions that determine PageRank, Domain Authority, E-E-A-T, or brand recognition.
Existing authority measurements remain valid for the surfaces they were calibrated against. But none of them adequately measures the AI-era conditions: machine-recognizability of the brand as a coherent entity in structured-knowledge systems; machine-credibility of the brand’s content for retrieval-augmented generation; machine-citability of the brand’s content as quotable references; machine-trust through inclusion in AI training corpora and citation by sources that AI systems weight heavily.
A new measurement is required — not as a replacement for existing authority measurements but as their AI-era counterpart. AVO introduces the Authority Score (Section 5) as that AI-era measurement.
2.3 The tactical layer: GEO, AEO, AIO
Three tactical disciplines have emerged to address specific surfaces in the AI search era.
Generative Engine Optimization (GEO) addresses how brands surface in synthesized AI outputs — the recommendations and explanations generated by ChatGPT, Claude, Perplexity, Gemini, and similar systems. GEO’s tactics include citation-friendly content engineering, structured data for generative consumption, and source-material authoring engineered for inclusion in AI training corpora.
Answer Engine Optimization (AEO) addresses extractive answer features — featured snippets, knowledge panels, AI Overviews, voice-assistant responses. AEO’s tactics include schema markup for snippet eligibility, FAQ content design, and direct-answer formatting for extractive surfaces. Industry usage of the term AEO is contested; some sources use it to mean Answer Engine Optimization (the mainstream definition), while others use it to mean Agent Engine Optimization, addressing schema-driven readiness for autonomous AI agents. This paper adopts the mainstream definition.
AI Optimization (AIO) addresses broad readiness for AI consumption, including content optimized for AI parsing, llms.txt configuration, and prompt-space coverage analysis. AIO is the most loosely defined of the three terms; some practitioners use it as a synonym for the entire emerging discipline.
These three tactical disciplines are real, useful, and addressed in their own published work. They are not, however, sufficient as a strategic discipline. Each addresses one tactical surface; none addresses the strategic question of how to organize work across all surfaces, how to measure progress in a coherent way, or how to verify outcomes against predicted readiness. Industry discourse has at times implied that these terms form a sequential pipeline, with each succeeding the others. This framing does not reflect how the work decomposes in operational practice. The three tactical disciplines address different surfaces and operate in parallel, not in sequence.
2.4 Adjacent published frameworks
Several frameworks have been published that address parts of the AI-era brand-discovery problem at the strategic level.
The AIVO Standard, authored by Paul Sheals and others, is a separately-published framework currently at version 3.5. AIVO Standard is published openly under Creative Commons Attribution 4.0 International, with DOIs assigned through Zenodo. Its core measurement is the Prompt-Space Occupancy Score (PSOS), supplemented by financial-translation metrics including AIVO Visibility Beta (AIVB) and Revenue-at-Risk (RaR). The framework operates a nine-stage methodology and emphasizes governance-grade auditability, ISO/IEC 42001 alignment, and EU AI Act compatibility. Although the acronym AIVO is similar to AVO, the disciplines are structurally distinct: AIVO operates a single-metric measurement structure focused on prompt-space occupancy with persistence and decay weighting, while AVO operates a paired measurement model with AS as predictive baseline and VS as empirical verification. AIVO and AVO are parallel methodologies that may inform one another; neither subsumes the other.
Assistive Agent Optimization (AAO), introduced by Jason Barnard, addresses the autonomous agent layer — optimization for AI agents acting on behalf of users. AAO names a frontier — agentic eligibility, distinct from visibility to user-facing assistants — that AVO version 1.0 does not yet specify. A future AVO version is expected to address agentic eligibility as an additional measurement layer rather than a replacement for the AS-VS model.
AI Assistive Engine Optimization (AIEO), developed by Barnard and Kalicube, addresses substantially overlapping concerns to AVO’s Visibility Score but with different vocabulary, different measurement structure, and a different theoretical foundation centered on the Algorithmic Trinity of pull-and-push channels.
The Architecture of Authority, published by Arcalea, comprises three layers: Information (RAG-optimized content), Reputation (Knowledge Graph entity identity), and Transaction (Universal Commerce Protocol for autonomous sales). Arcalea uses the term AEO to mean Agent Engine Optimization within this framework, contrasting with the mainstream definition.
2.5 The structural gap
These existing frameworks, individually and collectively, leave a structural gap. None offers all of the following in combination:
- A coherent strategic discipline above the tactical layer of GEO, AEO, AIO — one that contains the tactical specialties rather than competing with them.
- A paired measurement model that combines a predictive measurement (readiness for AI citation) with an empirical measurement (whether AI in fact cites the brand), allowing the predicted state to be validated against the observed outcome.
- A formal statistical treatment of measurement confidence using established methods — Wilson score intervals propagated through the rate-based formula.
- A first-class commitment to multilingual implementation, not as translation but as foundational architecture.
- A unified action catalog that names the canonical operational work in a single inventory.
- A defined operational loop that connects measurement to action and back to measurement, framing the discipline as a practice cycle rather than a static measurement framework.
AVO is structured to fill this gap. The discipline names the umbrella; the OMG Protocol provides the methodology; the AS-VS measurement model provides the paired prediction-and-verification instrument set. The three components are linked by the operational loop described in Section 7, which is the canonical AVO practice cycle.
3. The AVO Discipline
This section formally defines Authority and Visibility Optimization (AVO) as a discipline.
3.1 Formal definition
Authority and Visibility Optimization is the discipline of measuring and engineering brand authority and visibility for AI-mediated brand discovery. It defines what success means in the AI search era — when discovery surfaces are synthesized rather than listed — and provides the conceptual framework, the methodology, and the paired measurement instruments required to engineer for that success.
AVO is composed of three parts:
- The discipline itself — the conceptual framework that defines AVO’s domain, its claims, and its relationship to adjacent frameworks.
- The OMG Protocol — the methodology that prescribes the work practitioners perform to influence AVO outcomes.
- The paired measurement model — the Authority Score (AS) as the predictive measurement of citation readiness, and the Visibility Score (VS) as the empirical measurement of citation outcome.
The discipline is the why and the what-to-measure. The methodology is the how. The measurement is both the diagnostic baseline that directs the methodology and the verification that the methodology succeeded.
AVO is intended for any party engaged in engineering brand discovery for the AI search era — in-house brand and marketing teams, agencies and consultancies operating client engagements, and academic researchers studying the AI-mediated discovery surface. The methodology specifies what each must do; the calibration of detection pipelines, weights, and tooling is properly the implementer’s craft and varies by deployment context.
3.2 AVO as the AI-era measurement of authority
Authority is not a new concept. AVO does not introduce authority as a category; AVO introduces a measurement of authority calibrated for the AI search era. The lineage runs through PageRank for the link-graph era (Page et al., 1998), Domain Authority for the search-engine-ranking era, E-E-A-T for human-rater quality evaluation (Google, 2022), and brand authority for the human-mediated brand-recognition era (Aaker, 1996). Each measured authority for a specific discovery surface; each was calibrated for the conditions that produced authority on that surface. AVO extends this lineage by providing the measurement of authority calibrated for AI-mediated discovery — a continuation rather than a replacement. The detailed positioning of the Authority Score within this lineage is given in Section 5.2.
3.3 The umbrella claim
AVO is positioned as the umbrella discipline above the tactical layer of GEO, AEO, and AIO. The three tactical disciplines address different surfaces — synthesized AI outputs, extractive answer features, broad AI consumption readiness — and operate in parallel. AVO contains them by providing the strategic frame within which they are deployed: which surfaces matter for a given brand, in what proportion, with what success criteria, and how their performance is measured against shared instruments.
This containment is not subordinating. GEO, AEO, and AIO remain useful and named tactical specialties. Practitioners can deploy them under any organizational frame. AVO simply offers the strategic discipline that connects them to outcomes a brand can measure and act upon at portfolio scale.
3.4 The Digital Authority Funnel
The relationship between SEO, AVO, and the tactical layer is captured in the Digital Authority Funnel — a three-stage model with parallel tactical execution.
Stage 1: SEO (Foundation). The brand exists on the public web, is indexed by traditional search engines, and is reachable by the crawlers that feed both search ranking systems and AI training corpora. Foundation work — robots configuration, sitemap validity, performance, basic on-page structure — remains necessary in the AI era. Its sufficiency has changed; its necessity has not.
Stage 2: AVO (Strategic Discipline). The brand is machine-recognizable, machine-credible, and machine-citable. Authority is engineered through OMG; readiness is measured through AS; visibility is measured through VS. The two scores together form the diagnostic baseline and outcome verification of the practice cycle.
Stage 3: Tactical Execution Layer (GEO, AEO, AIO operating in parallel). Specific tactical execution within the AVO discipline — surfacing in generative answers, occupying extractive answer features, optimizing readiness for AI consumption.
The funnel is read top-to-bottom for dependency — Stage 3 depends on Stage 2, which depends on Stage 1. The funnel is read across-the-rows for operations — a mature brand operates at all three stages simultaneously, with different teams, time horizons, and ownership at each stage. Treating the dependency-ordering as a time-ordering is a common error: brands that postpone Stage 3 tactics until Stages 1 and 2 are “done” find that those stages are continuous practices, never done, and the postponement becomes indefinite.
3.5 The three commitments of AVO
AVO is defined by three commitments that distinguish it from alternative frameworks.
Commitment 1: Loop-first. AVO is the closed cycle of measurement, action, and verification. Measurement without action is a survey. Action without measurement is tactics. Verification without a baseline is outcome research. AVO is the loop that connects them: AS surfaces where readiness is deficient; OMG executes the work; VS verifies whether the work succeeded; re-measurement closes the cycle. A practice that runs only one component is not AVO — it is one component of AVO performed in isolation.
Commitment 2: Multilingual-first. AVO specifies first-class support for English, Indonesian, Japanese, Korean, and Traditional Chinese as primary languages. Multilingual support is foundational architecture, not feature flag — every datapoint, every measurement, every action is specified to operate across these languages without silent failure modes. Extension to additional languages is a matter of calibration, not architectural change.
Commitment 3: Portfolio-scale. AVO is built to operate across many domains simultaneously. The methodology, the measurement instruments, and the practice loop are designed to function at the scale of a brand portfolio (multiple domains, multiple Focuses per domain) rather than at the scale of a single page or a single keyword. This commitment shapes the architecture of every component that follows.
These three commitments — loop-first, multilingual-first, portfolio-scale — are non-negotiable. A practice that withdraws any of them is not AVO; it is something else.
4. The OMG Protocol — AVO’s Methodology
This section specifies the OMG Protocol, the methodology AVO prescribes to influence its measured outcomes.
4.1 OMG as the work between the measurements
The OMG Protocol is the methodology that bridges AVO’s two measurement instruments. The Authority Score (Section 5) provides the diagnostic baseline, surfacing where readiness is deficient at pillar, vector, or datapoint granularity. The Visibility Score (Section 6) provides the outcome verification, measuring whether the work executed in response to the AS findings produced the AI-mediated visibility it was intended to produce. OMG is the work that happens in between — the actions that convert diagnostic findings into outcomes, organized and named in a structure that practitioners can apply consistently.
This positioning is operationally definitive. A practitioner executing OMG actions without AS to direct them or VS to verify them is executing tactics, not practicing OMG. OMG is the methodology of converting measured weakness into measured outcomes through structured action — measurement is the entry condition and the exit condition of OMG practice.
4.2 The three pillars
OMG organizes authority engineering into three pillars: Optimize, Manifest, Generative. The order is not arbitrary. It corresponds to the three minimum gates a brand passes through to be cited in an AI-generated answer:
| Pillar | Gate | Failure mode |
|---|---|---|
| Optimize | Can AI systems engage with the brand at all? | The brand cannot be crawled, parsed, or structurally understood by automated systems |
| Manifest | Does the engagement produce an accurate representation? | AI systems form an inaccurate or shallow understanding of what the brand is |
| Generative | Is the represented brand trusted enough to be cited? | The brand is well-represented but not surfaced because external validation is absent |
Failure at any pillar is sufficient to prevent citation. A brand may be technically pristine (Optimize) and content-rich (Manifest) yet receive no AI citations because external authority signals are absent (Generative). Conversely, a brand may have abundant external authority (Generative) but receive degraded citations because AI systems cannot parse its content (Manifest). The three pillars are independently necessary.
The pillars also map to distinct organizational ownership and time horizons:
| Pillar | Owning team archetype | Time horizon |
|---|---|---|
| Optimize | Web engineering, technical SEO | Days to weeks |
| Manifest | Content, editorial, subject-matter experts | Weeks to months |
| Generative | Communications, public relations, partnerships, knowledge graph operations | Months to years |
A single team attempting to address all three pillars simultaneously typically fails at all three. Optimize requires engineering velocity. Manifest requires editorial discipline and domain expertise. Generative requires relationships and time. Conflating them in operational planning is the most common reason AVO programs stall.
4.3 Why three pillars
The OMG architecture maps directly onto the three minimum gates a brand passes through to be cited in an AI answer. A discipline with fewer pillars conflates gates that should be measured separately — typically merging Manifest and Generative into a single content-authority pillar that obscures whether a brand’s invisibility is a content problem or a recognition problem. A discipline with more pillars fragments interventions across team boundaries that do not exist in real organizations. Three is the minimum count that preserves the diagnostic distinction between consumption, representation, and trust.
4.4 The six measurement vectors
Within the three pillars, OMG specifies six vectors. Each vector groups datapoints that share a measurement type and an intervention type. Vectors are the level at which strategic prioritization happens — the question what should we work on next is answered at the vector level, before drilling down to specific datapoints.
| Pillar | Vector | What it covers |
|---|---|---|
| Optimize | V1.1 Signal Architecture | Structured data, schema markup, semantic HTML, metadata quality |
| Optimize | V1.2 Technical Health | Crawler accessibility, performance, security, canonical consistency, multilingual setup |
| Manifest | V2.1 Semantic Density | Topical relevance, content depth, attribution, entity recognition, claim density, originality, structural quality |
| Manifest | V2.2 Structural Legibility | Hierarchy, formatting, accessibility, identity clarity, update signals, chunk extractability |
| Generative | V3.1 Knowledge Validation | Citation strength, AI citation presence, Wikidata presence, knowledge graph depth |
| Generative | V3.2 Trust Alignment | Domain authority, trust signals, transparency indicators, external validation, content freshness |
The V1.1 / V1.2 split within Optimize separates the signals from the infrastructure — both fail modes look like AI cannot use this site but they require different fixes. The V2.1 / V2.2 split within Manifest separates substance from legibility — content can be deep but unparseable, or legible but shallow. The V3.1 / V3.2 split within Generative separates entity recognition from source trust — a brand can be known but not trusted, or trusted but not recognized as the right kind of entity.
4.5 The thirty canonical actions
The OMG Protocol includes a catalog of thirty canonical actions — the operational work practitioners perform within the three pillars. The full action catalog is provided in Appendix A. The pillar distribution is asymmetric: seven Optimize actions, ten Manifest actions, thirteen Generative actions. The asymmetry reflects the operational reality that Optimize work is concentrated in a smaller number of high-leverage actions, while Manifest and Generative work is distributed across more actions because each addresses a narrower aspect of the pillar’s overall remit.
A complete OMG practice does not require all thirty actions in every engagement. A typical engagement covers a subset selected based on what AS surfaced as deficient, the brand’s current maturity, and the operational priority of each pillar. Action selection happens at the granularity that the AS finding directs: when AS surfaces pillar-level weakness, OMG selection is broad; when AS surfaces specific datapoint weakness, OMG selection is narrow and targeted at the actions that affect those datapoints.
4.6 The OMG operational cadence
OMG is not only a methodology framework; it is an operational rhythm. Each pillar runs on its own cadence, dictated by the time horizon of the work and the ownership of the relevant team:
- Optimize sprints — one to two weeks. Short, scoped, deterministic. A vector of technical fixes can be planned, executed, and measured within two weeks.
- Manifest cycles — four to six weeks. Editorial commitments. A content depth program for a particular topic cluster takes weeks to produce and weeks more to be ingested by AI systems.
- Generative campaigns — two to four quarters. Long-form authority-building initiatives. Establishing Wikidata presence with proper sourcing, building citation patterns into authoritative reference domains, and earning third-party validation are quarter-to-year commitments.
The three rhythms are coordinated through a quarterly review that examines pillar trajectory, AS-to-VS verification across recent work, and the intervention pipeline. The quarterly review is the moment OMG transitions from measurement-and-intervention into strategic posture. It is the artifact most often shared with leadership, and the cadence at which the methodology contributes to organizational decision-making rather than only to operational improvement.
5. The Authority Score — AVO’s Diagnostic Baseline
This section specifies the Authority Score (AS), the AVO measurement of engineered readiness for AI citation.
5.1 What AS measures
The Authority Score is a 0-to-100 score quantifying the engineered readiness of a brand to be recognized and cited by AI systems. It is a domain-intrinsic measurement: AS measures what the brand has built, regardless of whether AI systems are currently surfacing it. AS answers the question: if AI systems were to engage with this brand fully, would they find the conditions that produce citation?
AS is the predictive measurement of citation readiness. It quantifies the conditions that determine citation likelihood — not citation itself, which is the outcome that the Visibility Score measures (Section 6). The two scores together form a paired prediction-and-verification instrument: AS predicts that the brand should be cited, given the conditions it has built; VS observes whether AI systems in fact cite it.
5.2 AS as the AI-era measurement of authority
AS is positioned as the next-generation measurement of authority, calibrated for the AI search era. Where PageRank measured authority through link-graph centrality (Page et al., 1998), where Domain Authority measured authority through backlink-graph reputation, where E-E-A-T measured authority through human-rater evaluation of expertise and trust (Google, 2022), AS measures authority through the conditions that AI systems use to determine citability: structural recognizability, content credibility for retrieval-augmented generation, citability of content as quotations, external validation through citation patterns and knowledge-graph presence.
The construct being measured is the same — authority as a brand’s standing as an authoritative source. The calibration is different — adapted to the discovery surface that synthesized AI answers represent. Practitioners familiar with PageRank, Domain Authority, or E-E-A-T will recognize the shape of AS as a continuation of established authority measurement, not a departure from it.
5.3 The aggregation chain
AS is computed by aggregating thirty-six datapoint scores into six vector scores, then into three pillar scores, then into a single Authority Score via a hybrid base formula and four sequential modifiers.
Datapoint scores → Vector scores → Pillar scores → Authority ScoreEach datapoint produces a 0-to-100 score, computed from observable evidence on the domain or from external sources. Vector scores are weighted averages of the datapoints they contain. Pillar scores are weighted averages of the vectors they contain. The within-vector and within-pillar weights are calibration parameters, not part of the published methodology.
A datapoint floor mechanism prevents zero-collapse: a single missing structural signal does not drag the parent vector to zero. Floors are configured per datapoint, reflecting the structural minimum each datapoint can reasonably produce given the absence of evidence rather than the presence of evidence against.
The aggregation chain is designed so that AS surfaces weakness at every layer. A practitioner reading an AS report can see which pillar is weakest, which vector within that pillar is weakest, and which specific datapoints are weakest. OMG action selection (Section 4.5 and Section 7.3) follows from these findings at whichever layer is most actionable.
5.4 The thirty-six datapoints
Each of the six vectors contains a defined set of datapoints. The full list is given below.
V1.1 Signal Architecture (5 datapoints)
| Datapoint | What it measures |
|---|---|
| schema-presence | Count and completeness of Schema.org structured data types present on pages |
| entity-schema | Whether the domain provides machine-readable Organization or entity-level structured data |
| structured-content-signals | Presence of machine-readable schema types specifically consumed by AI systems (Speakable, Dataset, ClaimReview, NewsArticle, FAQ structured forms) |
| semantic-html | Use of meaningful HTML elements (article, section, header, nav, main) rather than div-based layout |
| meta-completeness | Presence and adequacy of standard metadata fields — title, description, Open Graph, Twitter Card, language declarations |
V1.2 Technical Health (8 datapoints)
| Datapoint | What it measures |
|---|---|
| ai-crawler-access | Whether the domain’s robots and crawl-control configuration permits known AI crawlers |
| performance-score | Page-load and rendering performance, sourced from real-world or lab measurements |
| crawlability | Structural ability of crawlers to traverse the site |
| security-indicators | HTTPS, valid certificates, modern cipher suites, absence of mixed-content warnings |
| canonical-consistency | Whether canonical URL declarations are present, internally consistent, and aligned with the site’s URL structure |
| hreflang-implementation | Correctness of hreflang tag syntax and cross-referencing for multilingual sites |
| multilingual-readiness | Actual multilingual content availability with depth parity to the primary language |
| sitemap-validity | Presence, validity, and freshness of XML sitemaps |
V2.1 Semantic Density (7 datapoints)
| Datapoint | What it measures |
|---|---|
| topical-relevance | Semantic alignment of page content with its declared subject |
| content-depth | Substantive depth of content per page (meaningful word count after stripping boilerplate) |
| source-attribution-quality | Whether claims are inline-attributed to verifiable external sources |
| entity-recognition | Clarity with which named entities appear in content — recognizability to entity-extraction systems |
| claim-density | Frequency of factual claims, statistics, and specific assertions per unit of content |
| content-originality | Proportion of content original to the domain rather than syndicated or auto-generated |
| information-structure-quality | Quality of tables, comparison matrices, and tabular data |
V2.2 Structural Legibility (6 datapoints)
| Datapoint | What it measures |
|---|---|
| content-hierarchy | Use of heading structure (H1 through H6) reflecting actual content organization |
| chunk-extractability | Whether prose paragraphs are self-contained and extractable as standalone units |
| content-formatting | Presence of structural elements aiding extraction (lists, tables, code blocks, blockquotes) |
| accessibility-score | Accessibility of content to assistive technology, computed from WCAG-aligned indicators |
| source-identity-clarity | Visible publisher provenance — organizational name, editorial standards, dateline |
| content-update-signals | Visible evidence of maintenance and revision (last-updated dates, changelogs, version numbers) |
V3.1 Knowledge Validation (4 datapoints)
| Datapoint | What it measures |
|---|---|
| citation-strength | Quantity and quality of outbound links to authoritative external sources |
| ai-citation-presence | Whether AI systems actually cite the domain when answering questions in its category |
| wikidata-presence | Whether the entity exists in Wikidata with basic identifying properties |
| knowledge-graph-depth | Richness of the entity’s representation in knowledge systems |
V3.2 Trust Alignment (6 datapoints)
| Datapoint | What it measures |
|---|---|
| domain-authority-score | Coarse external authority proxy from established link-graph providers |
| trust-to-spam-ratio | Ratio of trust-positive signals to trust-negative signals on the domain |
| trust-signals | Presence of trust-establishing content (about pages, contact information, editorial standards) |
| transparency-indicators | Presence of accountability content (author bylines, correction policies, methodology disclosures) |
| external-validation-presence | Third-party validation across applicable channels (reviews, press, academic citation) |
| content-freshness | When content was published and last modified, with category-aware recency thresholds |
The thirty-six datapoint definitions are open methodology. Their detection pipelines, scoring thresholds, and within-vector weights are implementation-specific calibration.
5.5 The hybrid base formula
The base Authority Score is computed using a hybrid of weighted arithmetic mean and weighted geometric mean across the three pillars.
arith = O × wO + M × wM + G × wG
geo = O^wO × M^wM × G^wG
balance = geo / arith
raw = arith × balance^pWhere O, M, and G are the pillar scores; wO, wM, wG are pillar weights summing to one; and p is a balance exponent that controls how heavily imbalance between pillars is penalized.
The reasoning behind the hybrid is structural. Pure arithmetic-mean scoring rewards lopsided portfolios — a brand strong in one pillar can post a high score despite catastrophic weakness in another. Pure geometric-mean scoring is too punitive in the opposite direction — a single weak pillar can collapse the headline score even when the brand is fundamentally sound. The hybrid form interpolates between these two positions: when p approaches zero, the formula behaves arithmetically and tolerates imbalance; when p approaches one, the formula behaves geometrically and rewards balance. The actual balance exponent is calibrated against reference domains spanning the scoring bands.
5.6 The four sequential modifiers
After base computation, four sequential modifiers adjust the raw score. Each modifier addresses one structural condition the base formula cannot capture.
| Modifier | Trigger condition | Behavior |
|---|---|---|
| O-penalty | Optimize pillar below configured threshold | Multiplies the score by a penalty factor scaling linearly from a floor multiplier upward toward unity as Optimize approaches the threshold. Reflects that AI systems cannot recover content quality from a domain they cannot crawl. |
| G-penalty | Generative pillar below configured threshold | Same structural form as O-penalty, applied to Generative. Reflects that without external trust signals, internal content quality alone is insufficient for AI citation. |
| G-bonus | Generative pillar above configured threshold | Multiplies the score by a bonus factor scaling linearly from unity at the threshold upward to a maximum boost as Generative approaches 100. Rewards exceptional external authority. |
| Facade penalty | High Optimize plus Manifest combined with very low Generative | Detects domains that appear technically polished but lack genuine knowledge signals. Multiplies the score by a reduction factor proportional to the size of the readiness-without-trust gap. |
The four modifiers are sequential. Each is applied to the running raw score before the next is evaluated. The order — O-penalty, G-penalty, G-bonus, Facade — is structural: the first establishes the absolute floor (no crawl, no score), the next two adjust for external recognition, the last adjusts for the specific recognition-without-validation pattern.
5.7 The five scoring bands
The Authority Score reports into one of five bands. Band thresholds are calibration parameters; band names and structural meanings are open methodology.
| Band | Structural meaning |
|---|---|
| Critical | Fundamentally unprepared for AI visibility. Major Optimize-pillar deficits typically present. |
| Developing | Foundation in place but significant gaps remain. The default state of a competently-built but unoptimized site. |
| Strong | Well-optimized across all three pillars, with credible authority signals. |
| Elite | Genuinely elite AI readiness. Reserved for brands with full Optimize, Manifest, and Generative maturity. |
A fifth band exists below Critical, reserved for domains so structurally broken that even a Critical scoring would overstate their readiness — typically domains blocking all crawlers, returning errors on most pages, or producing no machine-readable content.
5.8 Confidence on the Authority Score
The Authority Score is reported alongside a confidence level computed from data completeness. The confidence is a function of the proportion of expected datapoints for which evidence was successfully collected, the reliability of the collection (failed crawls, blocked endpoints, timeouts, and degraded external sources reduce confidence), and the category of the domain (different categories have different baselines for which datapoints are meaningful).
When confidence falls below a threshold, the Authority Score is reported with an explicit reliability flag and recommendations for the data acquisition needed to lift confidence. Acting on a low-confidence score is methodologically equivalent to acting on a small sample.
6. The Visibility Score — AVO’s Outcome Verification
This section specifies the Visibility Score (VS), the AVO measurement of actual brand presence in AI-generated answers.
6.1 What VS measures
The Visibility Score is a 0-to-100 score quantifying the actual presence of a brand in AI-generated answers across the platforms the brand cares about. Where the Authority Score measures the conditions for citation, VS measures the citation outcome itself. VS answers the question: are AI systems in fact using this brand’s content, claims, and Focus in their answers?
VS is the empirical measurement of citation outcome. It is the proof — or counter-proof — of what AS predicted. The pairing is the structure of every empirical instrument: a predictive measurement of the conditions, an empirical measurement of the outcome, and the comparison between them as the basis for diagnostic interpretation. This pairing is described in detail in Section 7.
6.2 Focus, Prompt Book, Probe — the measurement vocabulary
Three terms structure VS measurement.
A Focus is a declared positioning statement representing what the brand wants to be known for. A Focus is not a keyword and not a topic; it is a strategic claim about the brand’s category and audience. Examples of well-formed Focuses: Japanese travel specialist, enterprise cybersecurity for healthcare, sustainable fashion brand. A Focus is the unit at which VS measures whether AI systems agree with a brand’s claimed positioning.
A Prompt Book is a structured set of prompts generated from a Focus, spanning three intent tiers — navigational (does the AI know the brand exists), category (does the AI surface the brand when asked about its category), and advisory (does the AI recommend the brand when a user requests guidance). The Prompt Book is generated automatically from the Focus and from search-volume signals.
A probe is a single execution of a prompt against an AI platform, with the response recorded and analyzed. Probes are the atomic unit of VS measurement; rates are computed across many probes per platform per measurement run.
6.3 The six probe-level signals
From each probe, six signals are extracted. Signal extraction follows a blind-extraction principle: the signal extractor sees only the brand and the response text, not the platform, the prompt, or the Focus. This isolation prevents bias.
| Signal | Type | What it captures |
|---|---|---|
| Mentioned | Binary | The brand appears in the response, in any framing |
| Recommended | Binary | The AI explicitly recommends or endorses the brand |
| Top pick | Binary | The AI singles out the brand as a primary or preferred option |
| Listed | Binary | The brand appears within an enumerated list the AI provides |
| Position | Ordinal | Where the brand falls within any list — first, second, third, or later |
| Cited | Binary | The AI provides a link or attribution to the brand’s website |
Sentiment is extracted as a separate companion metric from any probe in which the brand is mentioned. Sentiment is reported alongside VS as an independent diagnostic dimension; it is not part of the Visibility Score itself.
6.4 The three VS pillars
The Visibility Score is structured as three pillars that mirror progressive depths of brand presence.
| Pillar | Question | Composition |
|---|---|---|
| Presence | Does AI know you exist? | The mention rate across all probes. The baseline of visibility. |
| Endorsement | Does AI recommend you? | A weighted combination of the recommendation rate and the top-pick rate. Captures whether mentions translate into endorsement. |
| Prominence | How prominently? | A weighted combination of listed rate, position score, and citation rate. Captures the depth and quality of presence when the brand does appear. |
6.5 The VS formula
The headline Visibility Score is the weighted combination of the three pillars.
Presence = mention_rate × 100
Endorsement = (recommend_rate × wRec + top_pick_rate × wTop) × 100
Prominence = (list_rate × wList + position_score × wPos + citation_rate × wCit) × 100
VS = Presence × wP + Endorsement × wE + Prominence × wPrWhere the within-pillar weights and the across-pillar weights are calibration parameters. The structural choice in the formula — that VS is a weighted sum of pillar scores, each pillar a weighted sum of rate-based signals — is open methodology.
6.6 Confidence intervals via the Wilson score interval
Every rate that feeds the Visibility Score is a binomial proportion: a count of probes where some condition was true, divided by the total count of probes. Binomial proportions admit a well-known confidence interval — the Wilson score interval (Wilson, 1927) — which is more accurate than the simpler normal approximation, particularly for small samples or extreme proportions.
center = (p + z²/(2n)) / (1 + z²/n)
spread = (z / (1 + z²/n)) × √( p(1-p)/n + z²/(4n²) )
CI = [ center − spread, center + spread ]Where p is the observed rate, n is the total number of probes, and z is the standard normal quantile for the desired confidence level (1.96 for 95% confidence). The interval is propagated through each pillar formula and through the final VS-weighted combination to produce a confidence interval on the Visibility Score itself. The reported VS is therefore a point estimate with formal lower and upper bounds. The interval is graded — high, medium, low, or insufficient — based on its width. Insufficient-grade intervals indicate that probe coverage is too thin to draw conclusions; the methodology requires that decisions be deferred until coverage improves.
The propagation is intentionally conservative: rate intervals are treated as if independent, slightly overstating the true interval width because the underlying outcomes are positively correlated. The reported interval is therefore wider than the strictly correct interval would be — the safe direction for any disclosure to a stakeholder.
6.7 Brand recognition as a derived gate
Brand recognition is computed automatically from the navigational-tier probes within VS. It functions as a gate on the rest of the Visibility Score.
- When recognition exceeds a configured pass threshold, VS proceeds normally.
- When recognition falls between the warn and pass thresholds, VS is reported with a reduced-reliability flag.
- When recognition falls below the warn threshold, VS is reported with an explicit block status, indicating that interventions on category-level and advisory-level visibility are structurally premature until the brand is recognized at all.
The recognition gate prevents the methodology from generating recommendations that cannot succeed: there is no point in optimizing how AI systems describe a brand they do not know exists.
7. The AVO Practice Loop — AS, OMG, VS as a Closed Cycle
This section describes the operational loop that connects AVO’s three components. The loop is the canonical AVO practice cycle.
7.1 The loop, stated
AVO is structured as a closed operational loop:
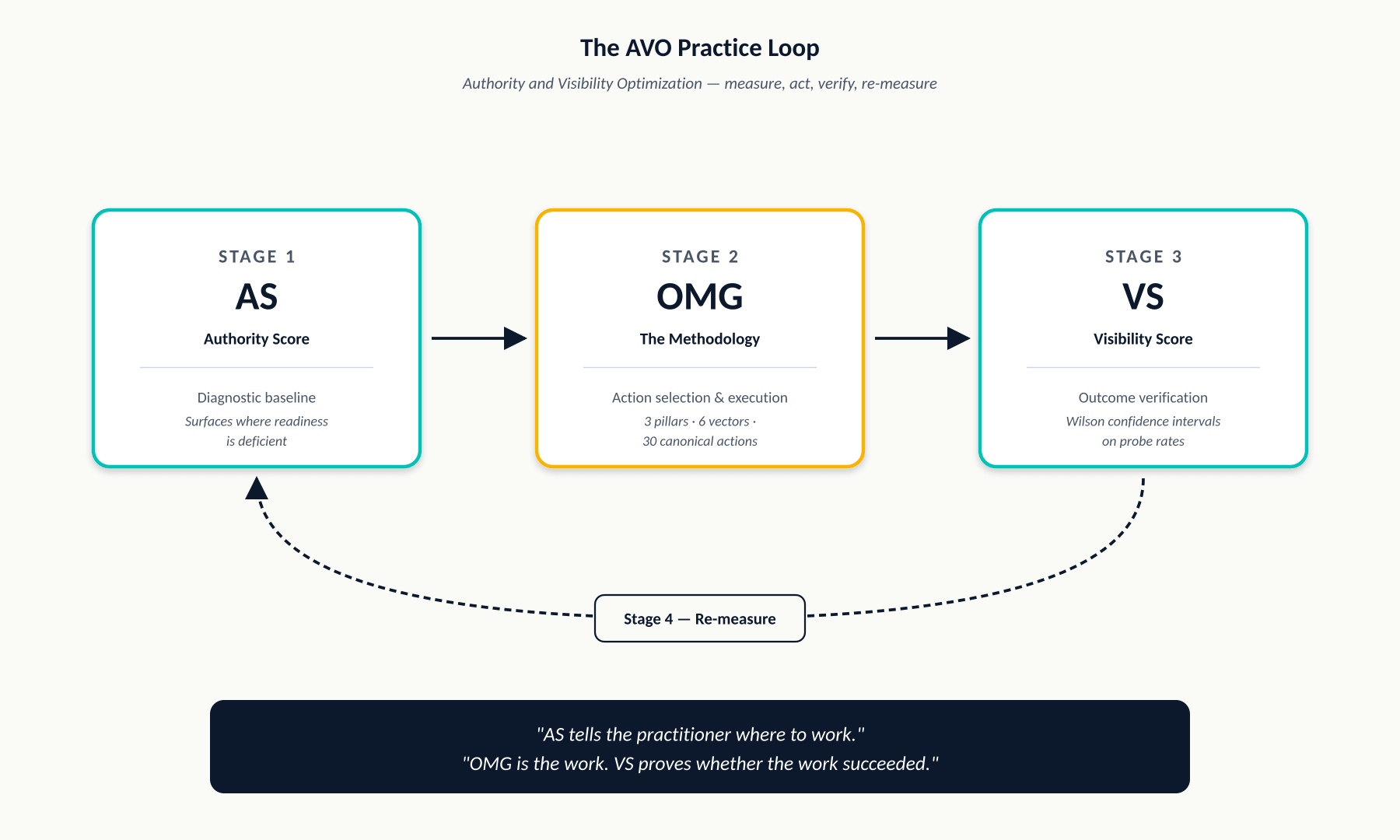
| Stage | Role |
|---|---|
| AS (diagnostic baseline) | Surfaces where readiness is deficient — at pillar, vector, or datapoint granularity |
| OMG (the work) | Selects and executes actions targeting what AS revealed |
| VS (outcome verification) | Measures whether the executed work in fact produced AI-mediated visibility |
| Re-measure | New AS measurement surfaces the next iteration’s findings; the cycle continues |
In the simplest possible statement: AS tells the practitioner where to work. OMG is the work. VS proves whether the work succeeded.
7.2 Why the loop matters
The loop is the structural definition of AVO practice. A practitioner running AS without acting on its findings is conducting a survey. A practitioner executing OMG actions without AS to direct them is executing tactics. A practitioner measuring VS without an AS baseline to compare against is conducting outcome research. None of these is AVO; AVO is the closed loop that connects them.
The loop also resolves a question that single-measurement frameworks cannot resolve: when visibility is low, is the cause a problem of authority (the brand is not engineered to be cited) or a problem of execution (the brand is engineered for citation but the work to surface it has not been done)? Without the AS-OMG-VS loop, this question is unanswerable from measurement alone — practitioners must guess. With the loop, the question is answerable structurally: if AS is low, the cause is authority, and OMG action is required to lift readiness; if AS is high but VS is low, the cause is execution, and OMG action is required in the Generative pillar — the actions that surface engineered authority into AI-mediated visibility (Appendix A, G-1 through G-13).
7.3 Granularity of OMG selection
AS surfaces weakness at three granularities — pillar, vector, and datapoint — and OMG action selection happens at whichever granularity is most actionable for each finding.
When AS surfaces pillar-level weakness (an entire pillar is significantly below the others), OMG selection is broad: actions across the weak pillar are prioritized over actions in stronger pillars. The intervention pattern is rebalancing.
When AS surfaces vector-level weakness within an otherwise strong pillar, OMG selection is medium-grained: actions affecting that specific vector are prioritized. The intervention pattern is targeted vector reinforcement.
When AS surfaces datapoint-level weakness with otherwise strong vector and pillar coverage, OMG selection is fine-grained: actions whose impact maps directly to those specific datapoints are prioritized. The intervention pattern is precise weakness elimination.
The methodology does not constrain practitioners to one granularity. AVO is calibrated to surface weakness wherever it exists and to support OMG action selection at the granularity that the finding warrants. Specific implementation tooling — software that translates AS findings into action-selection recommendations — is implementation-specific and outside the scope of this paper.
7.4 The cadence of the loop
Each component of the loop runs on its own cadence. AS measurement runs at a cadence sufficient to capture the impact of completed Optimize sprints and ongoing Manifest cycles — typically monthly in mature implementations, though specific intervals are implementation-specific. OMG actions run at the cadence of the relevant pillar — Optimize sprints in weeks, Manifest cycles in months, Generative campaigns in quarters. VS measurement runs at a cadence sufficient to detect changes in AI platform behavior — typically weekly to monthly, scaled to the size of probe coverage and the rate of new content publication.
What the methodology requires is that the loop be continuous rather than episodic. A brand operating AVO at scale runs all three components in parallel — measurement, action, and verification — rather than executing them as discrete sequential phases. The specific cadences are properly the practitioner’s craft, calibrated against the practitioner’s operational context. The quarterly review (Section 4.6) is the moment the cadences are coordinated across pillars and across the brand portfolio.
7.5 Confidence as a methodology constraint
Both AS and VS report confidence. Wilson confidence intervals on VS (Section 6.6), and the data-completeness confidence on AS (Section 5.8), constrain OMG action selection. When AS or VS confidence is low, the methodology requires that decisions be deferred until coverage improves. Acting on a low-confidence score is methodologically equivalent to acting on a small sample — it produces interventions whose justification cannot be empirically validated. The methodology treats this as a violation, not a tradeoff. The first action when confidence is low is to improve confidence (expand probe coverage, complete missing AS evidence collection), not to act on the uncertain scores.
7.6 The recognition gate as a methodology constraint
The brand recognition gate (Section 6.7) constrains OMG action selection in a specific way. When recognition is below the block threshold, OMG actions targeting category and advisory tiers are structurally premature: the AI does not know the brand exists, so optimizing how it describes the brand is impossible. The methodology requires that work proceed in the order recognition → category → advisory, regardless of which actions appear most appealing in the moment. The gate is enforced as part of the methodology, not as an optional best practice.
8. Multilingual Implementation
AVO specifies first-class support for five primary languages: English, Indonesian, Japanese, Korean, and Traditional Chinese. The choice of these five reflects the operational footprint in which the methodology has been calibrated and validated. Extension to additional languages is a matter of calibration, not architectural change.
8.1 Three structural commitments
Multilingual support in AVO is built on three structural commitments that distinguish it from multilingual-as-translation.
Commitment 1: Unicode-aware processing throughout. Tokenization, entity extraction, claim detection, content depth measurement — all use Unicode-aware character classes rather than ASCII-only patterns. A measurement that uses \w regex tokens silently fails on CJK content; a measurement that uses \p{L}\p{N} with the Unicode flag handles all five primary languages correctly.
Commitment 2: Language-specific date and entity patterns. Date conventions in Japanese and Chinese (year-month-day character forms: 年, 月, 日) differ structurally from English. Entity-formation conventions across all five languages — Japanese organizational suffixes (株式会社), Korean honorific patterns, Chinese name conventions — require explicit per-language pattern detection. A measurement that assumes English entity patterns produces silent failure on the other four languages.
Commitment 3: Neutral fallback rather than zero. When language detection encounters a script the implementation does not yet handle, the affected datapoints fall back to a neutral score rather than zero. This prevents silent failure modes: a brand with Korean content is not penalized to zero on Korean-content-relevant datapoints simply because the implementation has not been calibrated for Korean. The fallback is reported transparently so that the user knows the measurement is incomplete.
8.2 Why multilingual-first is methodological
Multilingual-first is not a feature; it is methodological architecture. A discipline that treats English as the default and other languages as translation produces systematically biased measurement outcomes for non-English brands. AVO’s commitment is that every datapoint, every action, every measurement is specified to operate across the five primary languages without silent failure modes, and that extension to additional languages is supported by calibration rather than by re-architecture.
This commitment also reflects the empirical context in which AVO was developed. The methodology was calibrated against deployments in APAC markets where multilingual measurement was a foundational requirement, not a feature to be added later. The commitment is preserved in the methodology specification so that the framework remains usable in deployment contexts beyond the original calibration markets.
9. Implementation Disclosure
The AVO discipline, the OMG Protocol, and the AS-VS measurement model described in this paper are implemented and operating at production scale at avonetiq.com. The implementation has measured authority and visibility for portfolio-scale deployments across multiple AI platforms and across the five primary languages specified in Section 8. Empirical evidence from this implementation informed the calibration of the Authority Score formula, the Visibility Score architecture, and the operational thresholds described throughout Sections 5 and 6.
The empirical context grounds the methodology against real measurement requirements and real failure modes. Multilingual implementation, in particular, was tested against actual non-English brand portfolios — a context that surfaced datapoint detection issues that would not appear in an English-only research environment. The Wilson confidence interval propagation through pillar formulas was developed in response to observed cases where probe coverage was insufficient and naive point estimates would have produced misleading guidance. The AS → OMG → VS practice loop described in Section 7 reflects how the implementation actually operates: measurement triggers analysis; analysis directs action; re-measurement verifies outcomes.
Specific calibration values, datapoint detection pipelines, prompt generation logic, platform weights, interpretation tooling, and operational software are implementation details outside the scope of this methodology paper. They are properly the practitioner’s craft, calibrated against the practitioner’s operational context, and not part of the open methodology. The methodology paper specifies the structure within which calibration happens; the calibration itself varies by implementation and over time.
10. Limitations and Future Work
This methodology version (AVO v1.0) is published with explicit acknowledgment of what it does not yet specify.
Multi-modal authority is currently absorbed into a single multimedia datapoint within V2.2. As multi-modal AI matures and image, video, and audio readiness become more important to AI-mediated discovery, multi-modal authority is likely to require dedicated datapoints and possibly a dedicated vector. This is anticipated in v1.1.
Agentic eligibility — whether a brand can be acted upon by autonomous AI agents, distinct from being merely visible to user-facing assistants — is not specified in v1.0. Agentic eligibility is a real and emerging concern as agentic AI surfaces evolve from prototype to production. AVO v2.0 is anticipated to address this evolution, likely as an additional measurement layer rather than a replacement for AS and VS.
Visibility retention across model retraining is not formally specified in v1.0. When AI platforms retrain their underlying models, brand visibility can shift dramatically — sometimes upward, sometimes downward, often discontinuously. A formal retention metric would capture this dynamic and support more nuanced practice loop interpretation. This is anticipated in v1.1.
Interpretation tooling is not formally specified. AVO v1.0 specifies the measurement instruments (AS, VS) and the methodology (OMG) and describes the operational loop that connects them (Section 7), but does not specify the interpretation tooling that practitioners use to translate AS findings into specific OMG action selections at scale. Implementations vary; specification of conformant interpretation tooling — including explicit requirements for how findings are surfaced, how actions are prioritized, and how outcomes are tracked back to predictions — may be addressed in a future version.
Financial-translation layer — converting visibility metrics into industry-specific revenue and exposure language — is not specified in v1.0. Adjacent frameworks (notably AIVO Standard) include such metrics. AVO’s first-class commitment is to measurement integrity; extending to financial translation requires careful methodological development to ensure the translation does not compromise the underlying measurement. This is anticipated in v1.1 or v1.2.
Reproducibility-receipt format for regulated industries — formal audit-grade documentation of probe-level measurements with chain-of-custody — is not specified in v1.0. This is anticipated as the methodology matures into deployments where formal audit is required.
Multilingual performance evaluation. AVO v1.0 specifies architectural commitments for multilingual support (Section 8) but does not present empirical evaluation of measurement performance across the five primary languages. The architecture is designed to operate without silent failure modes across English, Indonesian, Japanese, Korean, and Traditional Chinese; demonstrating that performance is in fact comparable across these languages requires controlled comparative study. This evaluation is anticipated in v1.1 alongside the multi-modal extension.
Calibration scope. AVO v1.0 is calibrated against APAC and English markets. Extension to additional markets — Spanish, Portuguese, Arabic, Hindi, and others — requires calibration work rather than methodological extension. The architecture supports this extension; the calibration is what is deferred.
These limitations are deliberately published so that practitioners adopting AVO know what the methodology does not yet do. A discipline that does not name its limitations cannot be improved by its community.
11. Conclusion
The AI search era has introduced a discovery surface that classical SEO frameworks cannot adequately measure or improve, and that existing tactical disciplines — GEO, AEO, AIO — address only in piecemeal. Existing strategic frameworks each address parts of the problem but none combines a conceptual frame, a methodology, paired measurement instrumentation, and a defined operational loop.
This paper has introduced Authority and Visibility Optimization (AVO) as the discipline that fills this gap. AVO is composed of three components, linked by an operational loop:
- A conceptual framework that defines brand discovery in the AI search era, positions the discipline as the umbrella above the tactical layer of GEO, AEO, and AIO, and frames AS as the AI-era counterpart to PageRank, Domain Authority, E-E-A-T, and brand authority — the next-generation measurement of an established concept.
- The OMG Protocol — a methodology organized into three pillars (Optimize, Manifest, Generative) and thirty canonical actions — that prescribes the work required to engineer authority and visibility, framed as the bridge between AS findings and VS outcomes.
- The paired measurement model — the Authority Score as predictive measurement of citation readiness, the Visibility Score as empirical measurement of citation outcome — connected by the AVO practice loop in which AS provides the diagnostic baseline, OMG executes the work, and VS verifies the outcome.
The discipline is multilingual-first, with first-class support for English, Indonesian, Japanese, Korean, and Traditional Chinese. The methodology and measurement model are implemented in production. The framework is published openly so that the AI-visibility field can converge on shared vocabulary and shared methodology rigor.
AVO does not claim to subsume the existing frameworks against which it is positioned. AIVO Standard, AAO, AIEO, the Architecture of Authority, and the tactical disciplines of GEO, AEO, AIO each address aspects of the AI-era brand-discovery problem in their own terms. AVO offers a different way to think about the problem — one in which a strategic discipline contains the tactics, in which two complementary measurements form a paired prediction-and-verification instrument, and in which the methodology is published with explicit boundary against the implementation calibration that is the practitioner’s craft.
The field will benefit from continued convergence: shared vocabulary, shared methodology rigor, shared empirical commitments. AVO is offered as a contribution to that convergence, not as a final word.
12. Acknowledgments
The author thanks Ryan Gondokusumo, Founding Partner at Avonetiq, for sustained conversation on the strategic positioning and operational framing of AVO and OMG, and for steering the work toward a discipline-led articulation. The Avonetiq engineering team contributed substantially to the operational refinement of the Authority Score’s hybrid formula, the Visibility Score’s three-pillar architecture, and the Wilson-interval propagation through pillar formulas. The firm’s APAC deployment context — spanning markets in Indonesia, Taiwan, and Japan — provided the multilingual operating environment that shaped the framework’s first-class commitment to language coverage across English, Indonesian, Japanese, Korean, and Traditional Chinese. Practitioners across the brands measured during the methodology’s development identified failure modes that would not have surfaced in a purely theoretical framework.
13. How to Cite
The canonical citation for this work is:
Wibowo, A. (2026). Authority and Visibility in the AI Search Era (v1.0). Avonetiq. https://doi.org/10.5281/zenodo.19948302
Author ORCID: 0009-0001-7686-0707
When referring to specific components of the framework in derivative work:
- “the AVO discipline (Wibowo, 2026)”
- “the OMG Protocol (Wibowo, 2026)”
- “the Authority Score (AS) as defined in Wibowo (2026)”
- “the Visibility Score (VS) as defined in Wibowo (2026)”
- “the AVO Practice Loop (Wibowo, 2026, §7)”
For component-level citation, including section references is encouraged. For implementation work, indicating both the methodology version and the implementation calibration is encouraged: “AVO v1.0 (Wibowo, 2026), implementation calibration by [implementer].“
14. References
- Aaker, D. A. (1996). Building Strong Brands. The Free Press.
- Brown, L. D., Cai, T. T., & DasGupta, A. (2001). Interval estimation for a binomial proportion. Statistical Science, 16(2), 101–133.
- Google. (2022). Search Quality Rater Guidelines: E-E-A-T update. Google Search Central. (Initial public release November 2015; E-E-A-T expansion December 2022.)
- Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.
- Page, L., Brin, S., Motwani, R., & Winograd, T. (1998). The PageRank Citation Ranking: Bringing Order to the Web. Stanford InfoLab Technical Report.
- Sheals, P. (2025–2026). AIVO Standard Methodology v3.5. Zenodo.
- Wilson, E. B. (1927). Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22(158), 209–212.
- World Wide Web Consortium. (2023). Schema.org Vocabulary. https://schema.org/
- Wikidata. (2026). Wikidata: The free knowledge base. https://www.wikidata.org/
Appendix A: The Thirty Canonical OMG Actions
The OMG Protocol comprises thirty canonical actions distributed across the three pillars. Each action is described with its action ID, name, pillar, the question it answers, scope, AS/VS connection, and dependencies.
Optimize (7 actions)
O-1: AVO Competitive Analysis & Benchmarking — Where does the brand stand relative to its competitive set on AI-mediated visibility, and which gaps represent the highest-leverage opportunities? Provides the baseline against which all subsequent AS and VS measurements are interpreted. No dependencies — kickoff action.
O-2: Unified Analytics & KPI Framework — Does the brand have the measurement infrastructure to quantify AVO outcomes? Foundational infrastructure for VS probe pipeline and AS measurement consumption. No dependencies.
O-3: Internal E-E-A-T & Authority Signals — Do AI systems encounter clear signals of expertise, experience, authoritativeness, and trustworthiness? Affects V2.2 and V3.2 datapoints. No dependencies.
O-4: Technical Infrastructure, Performance & International Foundation — Can AI crawlers, retrieval systems, and search infrastructure access, render, and parse the brand’s content reliably? Foundational for V1.2 across all eight datapoints. No dependencies.
O-5: Core Structured Data Foundation — Does the brand provide AI systems with machine-readable structured signals? Directly affects V1.1. Requires O-4.
O-6: Content Audit & Baseline Optimization — What is the current state of the brand’s content inventory, and which assets are closest to producing immediate AI-visibility improvements? Surfaces V2.1 and V2.2 datapoints. No dependencies.
O-7: Compliance & Trust Infrastructure — Does the brand meet the regulatory and trust-signaling baseline? Affects V3.2 and supports V2.2. Encompasses ongoing authority maintenance and link hygiene. Requires O-4.
Manifest (10 actions)
M-1: Question-Based Opportunity Mapping — What questions does the brand’s audience actually ask AI systems? Informs Prompt Book generation. Requires O-6.
M-2: Answer-First Content Architecture — When AI systems extract content, do they encounter answer-first structures? Affects V2.2. Requires M-1.
M-3: Dedicated FAQ & Knowledge Hubs — Does the brand provide structured, schema-enriched answer destinations? Affects V2.2 and V1.1. Requires O-5 and M-2.
M-4: Offline Authority Digitization — Are the brand’s offline authority assets represented in machine-readable form? Affects V3.2 and V2.1. Requires O-5.
M-5: AI Prompt & Answer Format Testing — Which content formats produce the highest extraction success rates across platforms? Improves all three VS pillars.
M-6: Evidence-Based Content & Citation Architecture — Are the brand’s claims supported by visible evidence and attribution? Affects V2.1; correlates with VS Prominence. Soft dependency on O-3.
M-7: Multimedia Content Optimization — Does the brand’s non-text content carry the metadata, transcription, and structural markup that AI systems require? Affects V2.2 and V1.1. Requires O-5.
M-8: Content Refresh & Decay Management — Does the brand maintain content currency at the cadence AI systems expect? Affects V3.2; sustained discipline preserves AS over time. Requires O-6.
M-9: Interactive Tool Development — Does the brand offer interactive utility that AI systems cite as resources? Affects V2.2 and V3.1. Requires O-5.
M-10: Content Hub Architecture & Internal Authority Flow — Is content organized in pillar-and-cluster structures that concentrate topical authority? Affects V2.1. Requires O-6.
Generative (13 actions)
G-1: External Entity Verification, Knowledge Graph & Local Authority — Is the brand recognized as a coherent entity by structured-knowledge systems? Affects V3.1 and V2.1. Requires O-3.
G-2: Advanced Topic Clustering — Does the brand demonstrate topical depth across coherent semantic territories? Affects V2.1 and V3.1. Requires O-6 and M-8.
G-3: Comprehensive Long-Form Content — Does the brand publish definitive, citation-worthy reference content? Affects V2.1 and V3.1. Requires G-2.
G-4: High-Authority Media Outreach — Does the brand earn citations from high-authority publications? Affects V3.2 and V3.1. Requires G-3 substantively.
G-5: Expert Social & Community Presence — Are the brand’s experts visible across the channels where authority is observed and reinforced? Strengthens V3.1. Requires O-3.
G-6: Advanced AVO Visibility Tracking & Multi-Platform AI Optimization — Is the brand’s visibility being measured and optimized continuously across AI platforms? Operationalizes the VS probe pipeline. Soft dependencies on O-2 and M-5.
G-7: Behavioral UX & Conversion Optimization — When AI-mediated visibility produces traffic, does the brand’s experience convert it into engagement signals? Behavioral signals contribute to V3.2. Requires O-4.
G-8: Original Research & Proprietary Data — Does the brand publish original research, surveys, datasets, or proprietary analyses? Strongly improves V3.1 and V3.2. Among the highest-leverage Generative actions.
G-9: Academic & Niche Citations — Is the brand cited in academic literature, peer-reviewed publications, and niche-authoritative venues? Affects V3.1 and V3.2. Requires G-3 and G-8.
G-10: Content Syndication & Republishing Partnerships — Is the brand’s content distributed across the network where AI systems and audiences encounter brand-citation patterns? Strengthens V3.1 and V3.2. Requires G-3.
G-11: Wikipedia & Wikidata Optimization — Is the brand established within the encyclopedic and structured-knowledge ecosystems? Affects V3.1 directly. Among the highest-leverage Generative actions. Requires G-1; benefits from G-8.
G-12: Predictive Content Strategy & Proactive AI Misinformation Correction — Does the brand establish first-mover authority on emerging topics and proactively monitor and correct AI-generated misinformation? Strengthens early VS positioning; protects existing AS. Requires O-1 and G-6.
G-13: Strategic Partnerships & Owned Audiences — Does the brand cultivate strategic partnerships and owned audience channels? Strengthens V3.2. Requires G-1 and G-5.
Outside the thirty: the Acceleration Layer
Some organizations choose to accelerate AVO outcomes through paid amplification — paid social, paid search, paid distribution of authority-building content. This work is not part of OMG methodology because OMG measures and improves earned authority and earned visibility. Paid amplification is a different discipline operating on a different theory of change. AVO recognizes the Acceleration Layer as an optional service category outside the thirty OMG actions.
Appendix B: Vocabulary — Canonical Terms
Core terms used throughout this paper, with canonical definitions.
AVO (Authority and Visibility Optimization). The discipline of measuring and engineering brand authority and visibility for AI-mediated brand discovery. Comprises a conceptual framework, the OMG Protocol methodology, and the paired AS-VS measurement model. The umbrella discipline above the tactical layer of GEO, AEO, AIO. The AI-era counterpart to existing authority measurement traditions including PageRank, Domain Authority, E-E-A-T, and brand authority.
OMG Protocol. AVO’s methodology. Three pillars (Optimize, Manifest, Generative), six measurement vectors, thirty canonical actions. Specifies the work practitioners perform to convert AS findings into VS outcomes.
Authority Score (AS). AVO’s predictive measurement instrument. A 0-to-100 score quantifying engineered readiness for AI citation, computed from a thirty-six-datapoint audit organized into six vectors and three pillars, via a hybrid base formula and four sequential modifiers. The diagnostic baseline of the AVO practice loop.
Visibility Score (VS). AVO’s empirical measurement instrument. A 0-to-100 score quantifying observed brand presence in AI-generated answers across measured platforms. Composed of three pillars: Presence, Endorsement, Prominence. Confidence intervals derived from Wilson score intervals on each underlying probe rate. The outcome verification of the AVO practice loop.
AVO Practice Loop. The closed operational cycle that defines AVO practice: AS surfaces where readiness is deficient; OMG executes work targeting the findings; VS verifies whether the work produced AI-mediated visibility; re-measurement closes the loop. The structural definition of AVO practice.
Optimize, Manifest, Generative. The three OMG pillars. Optimize addresses technical readiness for AI engagement. Manifest addresses content quality for accurate brand representation. Generative addresses external authority for AI trust.
Focus. A declared positioning statement representing what the brand wants to be known for. The unit at which VS measures whether AI systems agree with a brand’s claimed positioning.
Prompt Book. The structured set of prompts generated from a Focus, spanning navigational, category, and advisory intent tiers. The operational artifact that translates a Focus into measurable AI probes.
Probe. A single execution of a prompt against an AI platform, with the response recorded and analyzed for the six VS signals.
Wilson Confidence Interval. The statistical method used in AVO to compute confidence bounds on rate-based measurements. More accurate than the simpler normal approximation, particularly for small samples or extreme rates.
Brand Recognition. A derived metric computed from the navigational-tier probes within VS, functioning as a gate: when recognition is below the block threshold, category and advisory interventions are structurally premature.
Digital Authority Funnel. The three-stage model describing how SEO, AVO, and the tactical layer relate. Stage 1 is SEO foundation. Stage 2 is AVO strategic discipline. Stage 3 is the tactical layer of GEO, AEO, AIO operating in parallel.
Appendix C: Comparison with Adjacent Frameworks
The following table summarizes structural differences between AVO and adjacent published frameworks. Each framework is described in its own terms; the comparison is not evaluative.
| Framework | Discipline frame | Methodology component | Measurement model | Operational loop | Multilingual posture |
|---|---|---|---|---|---|
| AVO (this paper) | Authority and Visibility Optimization — umbrella discipline; AI-era authority measurement | OMG Protocol: 3 pillars, 6 vectors, 30 actions | Paired model: AS (predictive readiness) + VS (empirical outcome); Wilson confidence intervals | Defined: AS → OMG → VS → re-measure | First-class, 5 primary languages |
| AIVO Standard (Sheals) | AI Visibility — governance-frame discipline | 9-stage methodology with certification tiers | Single occupancy metric (PSOS) plus financial derivatives (AIVB, RaR) | Implicit through stage progression | English-Western-enterprise |
| AAO (Barnard) | Assistive Agent Optimization — agentic frontier | Tactical practices for agent interaction | (Emerging — measurement model not yet formalized) | (Emerging) | English |
| AIEO (Barnard, Kalicube) | AI Assistive Engine Optimization — pull-and-push channels | Algorithmic Trinity framework | Channel-specific measurements | (Implicit) | English |
| Architecture of Authority (Arcalea) | Three-layer framework (Information, Reputation, Transaction) | Tactical practices per layer | Layer-specific signals | (Implicit) | English |
| GEO (industry term) | Tactical specialty — synthesized AI outputs | Per-tactic guidance | Per-platform metrics | (None) | Variable |
| AEO (industry term, contested usage) | Tactical specialty — extractive answers | Per-tactic guidance | Per-feature metrics | (None) | Variable |
| AIO (industry term) | Tactical specialty — broad AI consumption | Per-tactic guidance | Per-readiness metric | (None) | Variable |
Practitioners may implement any of these frameworks, multiple frameworks in combination, or none. The choice depends on organizational context, deployment markets, and the specific AI-discovery questions the practitioner needs to answer. AVO is offered as one option in a growing field; the field will benefit from continued convergence rather than from any single framework subsuming the others.
End of Paper
Avonetiq · April 2026 Authority and Visibility in the AI Search Era · Wibowo (2026) Released under Creative Commons Attribution 4.0 International (CC BY 4.0)